Naive Bayes is a powerful classification algorithm which is used for predicting models.
In this post, you will discover the Naive Bayes algorithm for classification.
After reading this post you will get familiar with:
- What is Naive Bayes?
- How Naive Bayes algorithms work?
- What are the Pros and Cons of using Naive Bayes?
- Uses of Naive Bayes?
- Step by Step implementation in Python
- Tips to Improve the algorithm
What is Naive Bayes?
Let’s assume you are given an object. It’s round and cannot be eaten.
This round object can be anything a ball, a fruit or a shoe.
You will definitely assume that it will be a ball. But why so?
From childhood, we have seen a ball as round and something that cannot be eaten.

So from the features of an object, we can classify the object. And this the main objective of our algorithm.
Now let’s understand the Bayes theorem.
Let’s consider the cancer test example.
There is a city with 1% of people with cancer. Therefore P(c) = 0.01.
A cancer test has a 90% chance that it is positive if a person has cancer.
And a 90% chance that it is negative if a person does not have cancer.
We have to find the probability of having cancer.

From the given picture you can see that P(pos|c) = 0.9, similarly P(pos|c’) = 0.1
So, P(c,Pos) = P(c).P(Pos|c) = 0.009
Similarly P(c’,Pos) = P(c’).P(Pos|c’) = 0.099
P(Pos) = P(c,Pos) + P(c’,Pos) = 0.108
Now P(C|Pos) = 0.0833
Similarly, P(c’|Pos) = 0.9167
So the total probability is P(C|Pos) + P(c’|Pos) = 0.0833 + 0.9167 = 1
This could be tricky if you are not familiar with the probability.
I have given links at the end of the post which can help you learn Probability.
So now dive into the code. We will use the sklearn library to code our algorithm.
Implementation
from sklearn import datasets
from sklearn import metrics
from sklearn.naive_bayes import GaussianNBWe will import all the libraries we need
dataset = datasets.load_iris()Now we will load our dataset that is iris dataset
model = GaussianNB()
model.fit(dataset.data,dataset.target)After that we will assgin our model
expected = dataset.target
predicted = model.predict(dataset.data)Then we will predict the values and check whether the predicted values match the expected values.
print(metrics.classification_report(expected, predicted))
print(metrics.confusion_matrix(expected, predicted))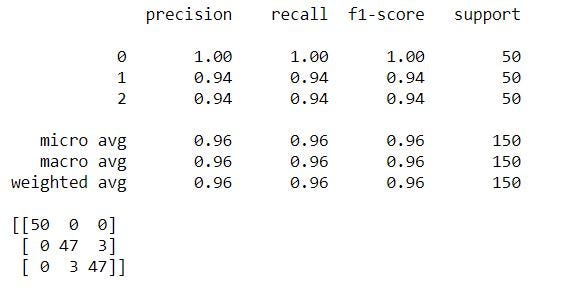
We can see the precision of our classifier and the score.
So that’s all for this post stay tuned for more machine learning.
Resources
https://www.khanacademy.org/math/statistics-probability
Other Posts
https://learn-ml.com/index.php/2019/05/29/logistic-regression-step-by-step-guide-in-python/
